Convert HTML to PDF with Python

There is a wide variety of choices when it comes to creating a PDF from HTML in Python. In this article, we'll look at some open-source and commercial tools that are available and share our recommendations to help you find the tool that works best for you.
According to this article:
The Portable Document Format (PDF) is a file format developed by Adobe in 1993 to present documents, including text formatting and images, in a manner independent of application software, hardware, and operating systems.
Why Converting HTML to PDF
HTML is used to create layouts in web applications and sometimes you'll need to provide the information that's already presented to users in HTML to a PDF document. For instance, in eCommerce apps, you most likely need to provide documents such as, statistical reports, tickets and invoices to users as PDF documents so they can save them locally for records, have them emailed or print them.
Let's take the example of an invoice, the application may already display the information in the invoice with HTML and CSS, then provide a button that users can click to download the PDF document of the invoice for their records. That means the information is already formatted and available to the users. You only need to provide that in PDF format for download and printing. Therefore, a good solution to consider would be to check if it is possible to use that HTML and CSS to generate a PDF version.
PDF is a portable document format that's good for printing. CSS, also has a specification for print, refereed to as the Paged Media module. This makes CSS convenient for formatting things like books, catalogs and brochures which are not designed to be a web page in the first place.
The biggest difference, and conceptual shift, is that printed documents refer to a page model that is of a fixed size. Whereas on the web we are constantly reminded that we have no idea of the size of the viewport, in print the fixed size of each page has a bearing on everything that we do. Due to this fixed page size, we have to consider our document as a collection of pages, paged media, rather than the continuous media that is a web page. Source
You may also want to check out this article for more details about designing for print with CSS.
How to Generate PDF Files from HTML
For simple use cases, you can generate a PDF file right from your web browser without installing any third-party tool, by simply choosing to print to PDF instead of a printer. This may be enough for some use cases but it's also far from being satisfactory! Some of the inconveniences, include the presence of the headers and footers which are added by default when you print content from a webpage. It will also be formatted according to your print style-sheet in case there is one.
In case, you need more control, you may want to use a free tool called WeasyPrint which is a free and open-source software under the BSD license, designed for Python 3.5+ but it doesn’t fully implement all of the Paged Media features, however it has more than what's provided with the web browser out of the box.
Other tools which claim to support conversion from HTML and CSS to PDF include PDFCrowd, which allows you to generate PDF and screenshots from web pages and HTML documents in your applications and provides integrations with popular programming languages including Python but we can't find, in the documentation, what features of the Paged Media specification are supported.
There are also many HTML to PDF libraries that are available for Python developers such as:
- Pyppeteer: Unofficial Python port of puppeteer JavaScript (headless) chrome/chromium browser automation library.
- xhtml2pdf: An HTML to PDF converter using Python, the ReportLab Toolkit, html5lib and PyPDF2. It supports HTML5 and CSS 2.1 (and some of CSS 3). It is completely written in pure Python, so it is platform independent. The main benefit of this tool is that a user with web skills like HTML and CSS is able to generate PDF templates very quickly without learning new technologies.
If you prefer to use JavaScript instead of Python, check out this article that lists some of the free and commercial tools for converting HTML to PDF with JavaScript.
Using Printing User Agents
As mentioned before, if you want to properly produce paginated and formatted output and still stick to an HTML-and-CSS to PDF solution, you need a tool that implements the Paged Media features, you need to take a look at printing user agents.
According to this Wikipedia article:
In computing, a user agent is software (a software agent) that is acting on behalf of a user, such as a web browser that "retrieves, renders and facilitates end user interaction with Web content". An email reader is a mail user agent.
Popular examples of user agents are web browsers. You can identify user agents using User Agent Strings.
A browser’s user agent string (UA) helps identify which browser is being used, what version, and on which operating system. When feature detection APIs are not available, use the UA to customize behavior or content to specific browser versions.Source
Just like there are user agents for retrieving and rendering web pages i,e web browsers, there are also printing user agents which are designed for printing from HTML and CSS, and provides APIs for generating the PDF files. These User Agents have a better implementation of the Paged Media specification and better support for the CSS Fragmentation properties which allows you to have more control over the formatting your the PDF files.
CSS Fragmentation is a CSS module that defines how content is displayed when it is divided (fragmented) into several pages, regions or columns. Fragmentation occurs in many situations; in printing, it mainly occurs when an element spans a page break.
Some of the well-known printing user agents include:
- Prince
- Antenna House
- PDFReactor
Before you can use these printing user agents in your web applications, you'll need to buy a license and install them on your server but the problem with these tools is that they are expensive which may not be worth it for simple use cases. But if your business rely on producing printed documents with them, they can very well pay for themselves by reducing the development time.
Using DocRaptor
If you still need to use the Prince API and don't want to host your own server or can't afford to buy the expensive license, you can use its API on a pay per document basis, via the DocRaptor service which provides an API powered by the PrinceXML HTML-to-PDF engine, with powerful support for headers, page breaks, page numbers, flexbox, watermarks, accessible PDFs, and much more.
You can use DocRaptor from within your Python application using the docraptor package.
Let's get started by creating a virtual environment using the following command:
$ python3 -m venv env
Next, activate thee virtual environment using the following command:
$ source env/bin/activate
Next, you can install docraptorfrom PyPI using the following command:
$ pip install --upgrade docraptor
At the time of this writing docraptor v2.0.0 is installed.
Next, create a file that may be called convert.py:
$ touch convert.py
Open the file and start by adding the following imports:
import docraptor
import sys
Next, create and instance of docraptor.DocApi as follows:
doc_api = docraptor.DocApi()
doc_api.api_client.configuration.username = 'YOUR_API_KEY_HERE' # this key works for test documents
doc_api.api_client.configuration.debug = True
We use YOUR_API_KEY_HERE as username for testing the API without paying (test documents are free but watermarked) and we set debug to True to show debugging information on the terminal.
Next, add the following code to invoke the create_doc of the API as follows:
try:
create_response = doc_api.create_doc({
"test": True,
"document_url": sys.argv[1],
"name": sys.argv[2],
"document_type": "pdf"
})
with open("./%s"% (sys.argv[2]), "wb") as f:
f.write(create_response)
print ("Wrote PDF to ./%s" % (sys.argv[2]))
except docraptor.rest.ApiException as error:
print(error.status)
print(error.reason)
print(error.body)
We call the API inside a catch..except block to catch any errors and print them on the console. We pass the first argument of our script to document_url to provide the URL of the page we want to convert to PDF; and the second argument as the file name of the outputted PDF file. We can also supply HTML content directly using document_content.
We set document_type to pdf to output a PDF file of the supplied URL; we can also use xls or xlsx formats.
Save the file. head back to your terminal and run the following command to test our script:
$ python3 convert.py https://www.techiediaries.com/convert-html-pdf-python myfile.pdf
We pass the URL of the web page we want to convert as the first argument to the script, and the name of the output file as the second argument. The PDF file will be outputted on the same folder where the script resides.
You can find more details from the docs or more code examples in this GitHub repository.
Using IronPDF Python
When working with Python, IronPDF emerges as a reliable solution for converting HTML into PDFs. This powerful PDF library allows Python developers to effortlessly transform HTML content into high-quality PDF files, ensuring the formatting and layout remain consistent. Ideal for creating reports, invoices, or any document that needs to be in PDF format with precision, IronPDF stands out for its effectiveness. If you’re seeking a straightforward way to create PDFs from HTML in Python, I recommend exploring IronPDF. Their detailed tutorials offer a comprehensive guide to getting started.
Implementation:
Implementing IronPDF to convert HTML to PDF is very easy. You’ve to follow some simple steps, and your HTML will be converted into the perfect PDF within a matter of seconds. Let’s go through the steps:
Step 1: Install IronPDF
First, ensure that IronPDF is installed in your Python environment. You can do it using the following command:
pip install ironpdf
Step 2: Import IronPDF Library
First, import the IronPDF modules in the Python Script. Use the following command to import it. Make sure that you use this statement at the top:
Import statement for IronPDF Python
from ironpdf import *
Step 3: Add License Key
Before starting the conversion, it’s important to add your IronPDF license key to work it at its full potential in the production stage. You can get your license key from the license page of IronPDF Python.
License.LicenseKey = "IRONPDF-LICENSE-KEY"
Step 4: Convert HTML To PDF
Here comes the main point of this guide. We’ll use the RenderHtmlAdPdf method to convert HTML to the PDF document. We’ll provide the HTML String as the parameter. This string can contain CSS and JavaScript, too, to beautify the generated PDF. Here is the sample code:
import sys
from ironpdf import *
License.LicenseKey = "IronPDF-License-Key"
html_string = """
<!DOCTYPE html>
<html>
<head>
<title>Bootstrap HTML to PDF Test Document</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css">
</head>
<body>
<div class="container">
<h1 class="mt-5 mb-3">Main Heading</h1>
<p>This is a sample paragraph to test text rendering in PDF with Bootstrap styles.</p>
<h2>Lists</h2>
<ol class="list-group mb-4">
<li class="list-group-item">First Ordered Item</li>
<li class="list-group-item">Second Ordered Item</li>
</ol>
<h2>Table</h2>
<table class="table table-bordered table-striped mb-4">
<thead>
<tr>
<th>Header 1</th>
<th>Header 2</th>
</tr>
</thead>
<tbody>
<tr>
<td>Row 1, Cell 1</td>
<td>Row 1, Cell 2</td>
</tr>
<tr>
<td colspan="2">Row 2, Single Cell spanning two columns</td>
</tr>
</tbody>
</table>
<h2>Images and Links</h2>
<img src="https://via.placeholder.com/150" class="img-fluid mb-3" alt="Placeholder Image">
<a href="https://www.example.com" class="btn btn-primary mb-4">External Link</a>
</div>
</body>
</html>
"""
Using IronPDF to convert HTML to PDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html_string)
pdf.SaveAs("HTML String To PDF.pdf")
By executing this program, you’ll get the following output, which matches our HTML input.
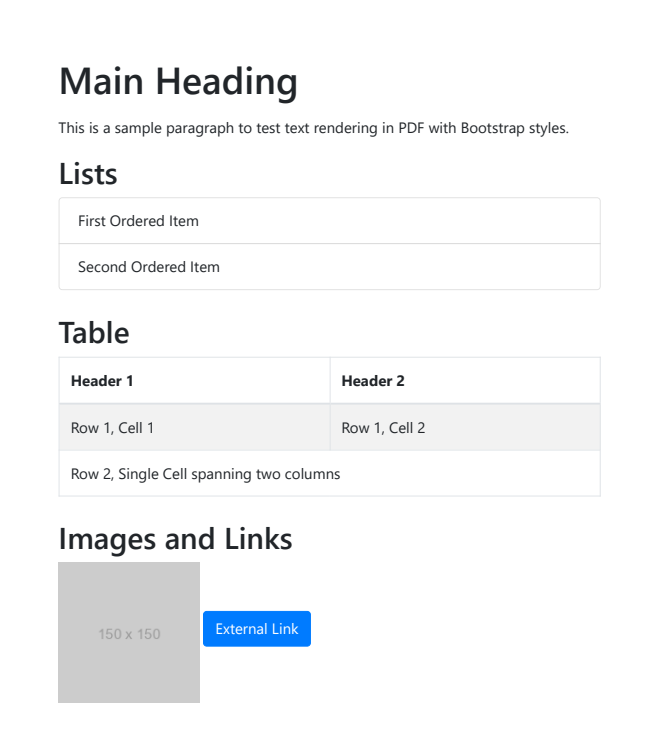
If you don’t want to mess up your code, have the code in an HTML file. Then, you can use the RenderHtmlFileAsPdf method to convert the HTML file to a PDF document.
Using IronPDF, you can also convert URLs to PDFs while preserving the formatting of the web page. For URL to PDF, IronPDF offers RenderUrlAsPdf method.
Conclusion
When printing HTML content of web pages to PDF, you can use the web browser for simple cases such as continuously scrolling webpages but if you want to to generate multi-page documents, you need to use tools that implement the Paged Media specification; one of these tools is Prince but this maybe expensive plus you'll have to host your own server. This is where DocRaptor may be you best bet as it makes use of the Prince API behind the scene while offering a pay per document plan.
- Author: Ahmed Bouchefra Follow @ahmedbouchefra
-
Date:
Related posts
